(2023.03.04)
Semantic Segmentation 논문 검토 2부
– 학위 논문 제목: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (2015)
– https://arxiv.org/pdf/1511.00561v3.pdf
'추천 관련글,

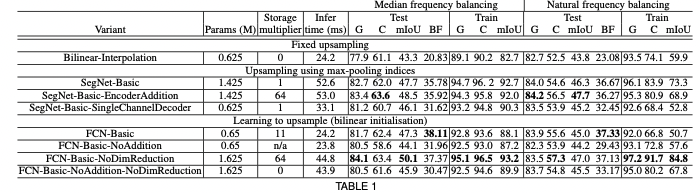
모델 아키텍처
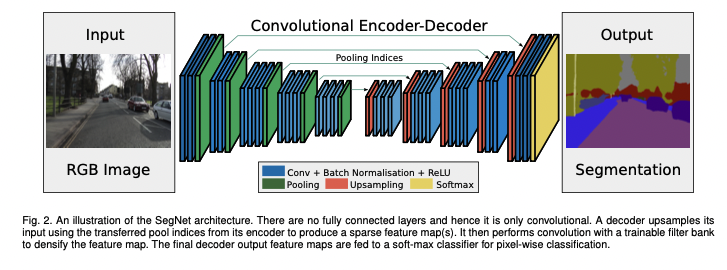
SegNet은 인코더-디코더 구조입니다.
– 인코더는 vgg16에서 13개의 conv 레이어를 가져왔습니다. (해상도가 감소하고 매개변수가 증가함에 따라 완전히 연결된 레이어를 제거했습니다.)
– 해당 디코더도 13개의 레이어로 구성되어 있습니다.
– 마지막 디코더의 출력은 다중 클래스 softmax 분류기를 거치고 각 픽셀의 클래스 확률로부터 최종 분할 맵 결과가 나옵니다.
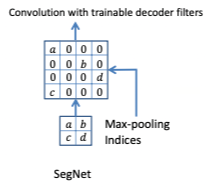
SegNet의 업샘플링 방법은 아래 그림과 같습니다.
인코더에서 2×2 max pooling을 할 때 max pooling index를 저장하고, decoder에서 upsampling을 할 때 적절한 위치에 받아서 upsampling한다.
저자는 SegNet을 DeconvNet & UNet과 비교했습니다.
– 3개 모델 모두 업샘플링 과정이 다름
SegNet은 매개변수가 적고 메모리를 덜 사용하는 모델입니다.
이 두 가지가 주요 비교 대상인 것 같습니다.
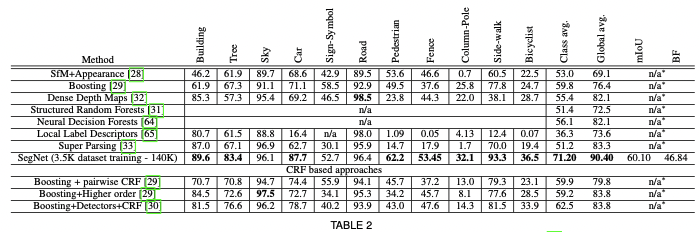
실험